Working in analytics these days, the concept of big data has been firmly established. Smart engineers have been developing cool technology to work with it for a while now. The Apache Software Foundation has emerged as a hub for many of these - Ambari, Hadoop, Hive, Kafka, Nifi, Pig, Zookeeper - the list goes on.
While I'm mostly interested in improving business outcomes applying analytics, I'm also excited to work with some of these tools to make that easier.
Over the past few weeks, I have been exploring some tools, installing them on my laptop or a server and giving them a spin. Thanks to Confluent, the founders of Kafka it is super easy to try out Kafka, Zookeeper, KSQL and their REST API. They all come in a pre-compiled tarball which just works on Arch Linux. (After trying to compile some of these, this is no luxury - these apps are very interestingly built…) Once unpacked, all it takes to get started is:
./bin/confluent start
I also spun up an instance of nifi, which I used to monitor a (json-ised) apache2 webserver log. Every new line added to that log goes as a message to Kafka.
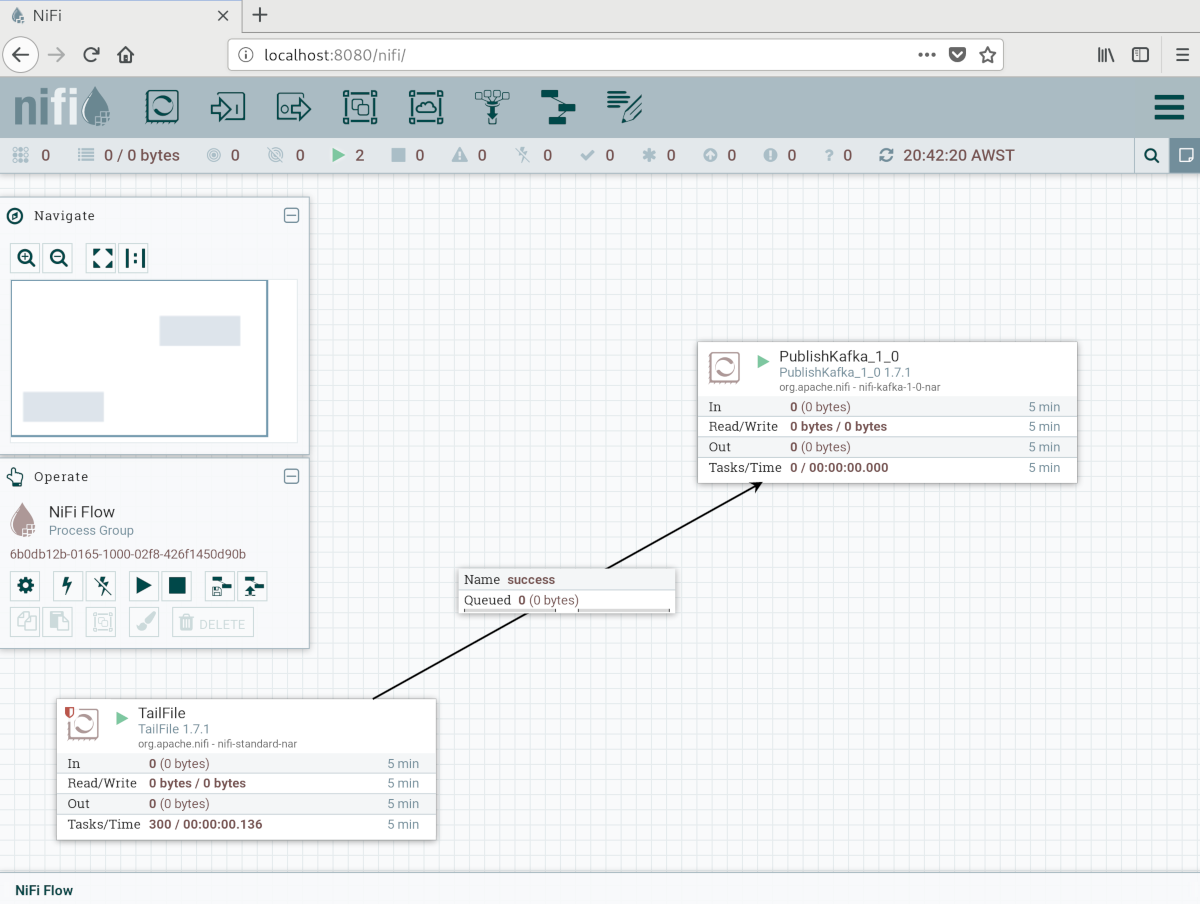
Figure 1: Apache Nifi configuration
A processor monitoring a file (tailing) copies every new line over to another processor publishing it to a Kafka topic. The Tailfile monitor includes options for rolling filenames, and what delineates each message. I set it up to process a custom logfile from my webserver, which was defined to produce JSON messages instead of the somewhat cumbersome to process standard logfile output (defined in apache2.conf, enabled in the webserver conf):
LogFormat "{ "time":"%t", "remoteIP":"%a", "host":"%V", "request":"%U", "query":"%q", "method":"%m", "status":"%>s", "userAgent":"%{User-agent}i", "referer":"%{Referer}i", "size":"%O" }" leapache
All the hard work is being done by Nifi. (Something like
tail -F /var/log/apache2/access.log | kafka-console-producer.sh --broker-list localhost:9092 --topic accesslogapache
would probably be close to the CLI equivalent on a single-node system like my test setup, with the -F option to ensure the log rotation doesn't break things. Not sure how the message demarcator would need to be configured.)
The above results in a Kafka message stream with every request hitting my webserver in real-time available for further analysis.
Posted on Tuesday 11 September 2018 at 21:09